{kind=link}
KANvas is an open-source framework that classifies labor market job roles by distinguishing between traditional data science and GenAI-oriented positions. It leverages Kolmogorov–Arnold Networks (KANs) to provide an interpretable, compact, and effective classification model using skill-based inputs extracted from real-world job ads.
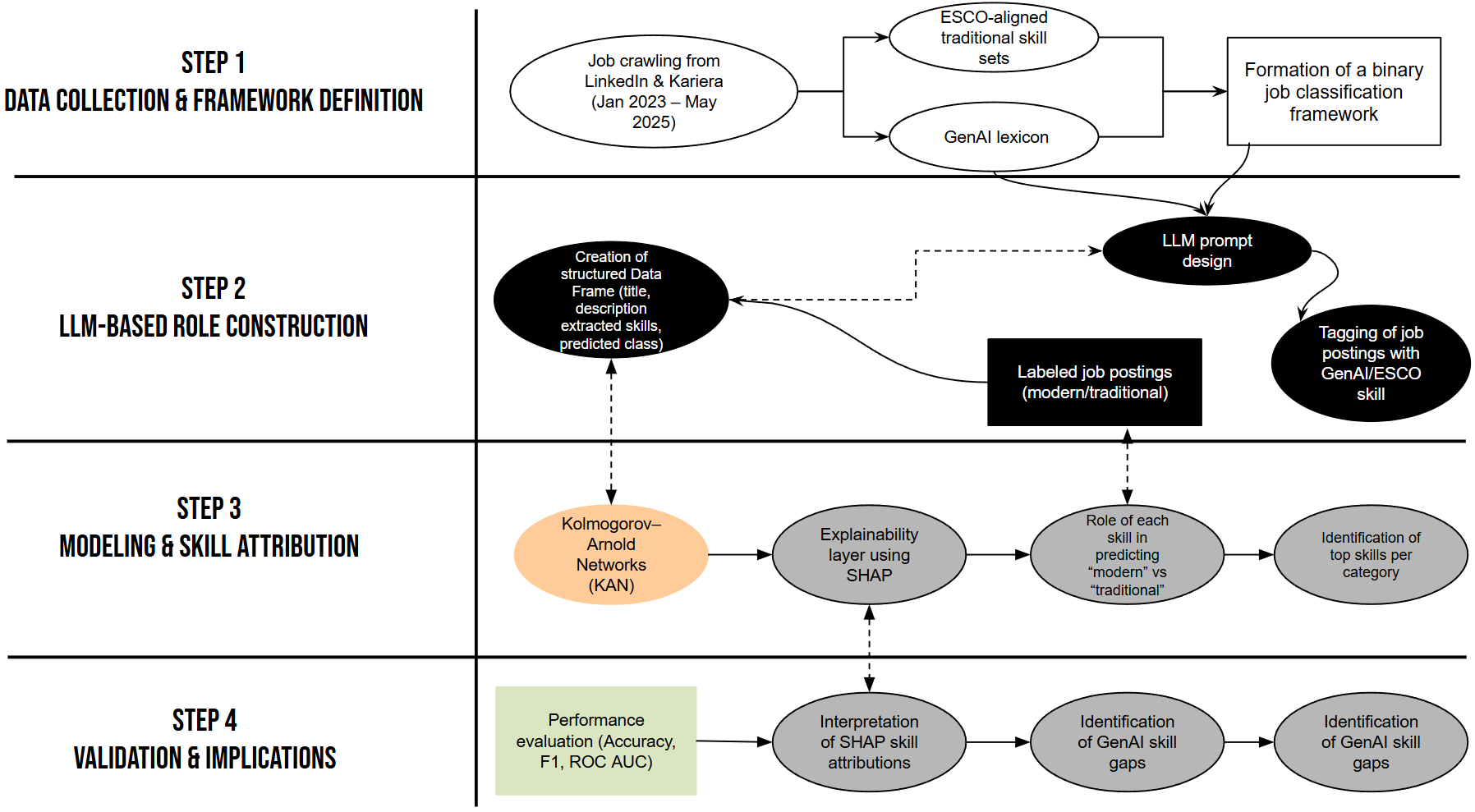
KANVAS follows a four-stage methodology:
- COLLECT – Scrape and clean from online job ads
- CLASSIFY – Use an LLM-based filter to label jobs as
modernortraditional - MODEL – Train a Kolmogorov–Arnold Network on sparse multi-hot encoded skill vectors
- EXPLAIN – Interpret results with SHAP to reveal key skill indicators
KANvas/
├── data/ # Raw and processed job datasets
│ ├── raw_jobs.csv
│ └── processed_jobs.csv
│
├── notebooks/ # Jupyter notebooks for experimentation
│ ├── 01_data_collection.ipynb
│ ├── 02_classification.ipynb
│ └── 03_train_kan.ipynb
│
├── scripts/ # Reusable Python scripts
│ ├── extract_skills.py
│ ├── train_kan_model.py
│ └── shap_analysis.py
│
├── results/ # Output plots, metrics, model files
│ ├── shap_modern.png
│ └── shap_traditional.png
│
├── models/
│ └── kan_model.pt
│
├── docs/
│ └── figures/
│ └── kanvas_schema.png
│
├── LICENSE
├── README.md
├── requirements.txt
└── .gitignore
- Interpretable classification of jobs using Kolmogorov–Arnold Networks (KANs)
- SHAP visualizations for skill-level explainability
- Skill extraction pipeline aligned with ESCO and GenAI lexicons
- Fully reproducible in PyTorch and Python
- Python 3.10+
- pandas, numpy, scikit-learn
- torch, pykan, shap
- tqdm, matplotlib
git clone https://github.com/your-org/kanvas.git
cd kanvas
pip install -r requirements.txtMODEL_PATH=models/kan_model.pt
DATA_PATH=data/processed_jobs.csv
python scripts/extract_skills.pypython scripts/shap_analysis.py